
임베딩과 벡터란
최근 LLM이 대세로 떠오르면서 "임베딩", "벡터" 등의 단어를 듣게 되는 일이 많아졌다. NLP에서 임베딩과 벡터란 무엇일까? NLP에서 사용하는 토큰이란 단어나 형태소 등의 자연어이다. 이 자연어를 기계가 이해할 수 있는 수학적 표현인 벡터로 바꾸는 것을 임베딩이라고 한다. 쉽게 이야기하자면 언어를 숫자로 바꾸는 게 임베딩이다.
ChatGPT 등 몇몇 서비스에서는 임베딩 기능도 API를 호출해서 쓸 수 있다. 만약 임베딩을 해야 한다면 좋은 언어 모델을 가진 서비스의 임베딩을 쓰는 게 필수적인데, 이 부분이야말로 LLM에서 가장 공수가 많이 들어간 부분이기 때문이다. 왜 좋은 임베딩을 쓰는 것이 필수적인지를 여러 임베딩 방법을 배우면서 알아보자.
One-hot vector
임베딩 중 가장 단순하고 쉬운 방법으로는 One-hot vector 방법이 있다. 예를 들어서 임베딩을 생성해야 하는 단어가 N개 있다고 하면, 1*N 행렬을 만든 후 해당 단어를 의미하는 위치에는 1을, 나머지 위치에는 0을 주어서 그 단어를 표현하는 방식이다. 예를 들어서 아래의 예시에서 Apple은 [1, 0, 0, ..., 0, 0, 0]이 되고, Woman은 [0, 0, 0, ..., 0, 0, 1]이 된다.
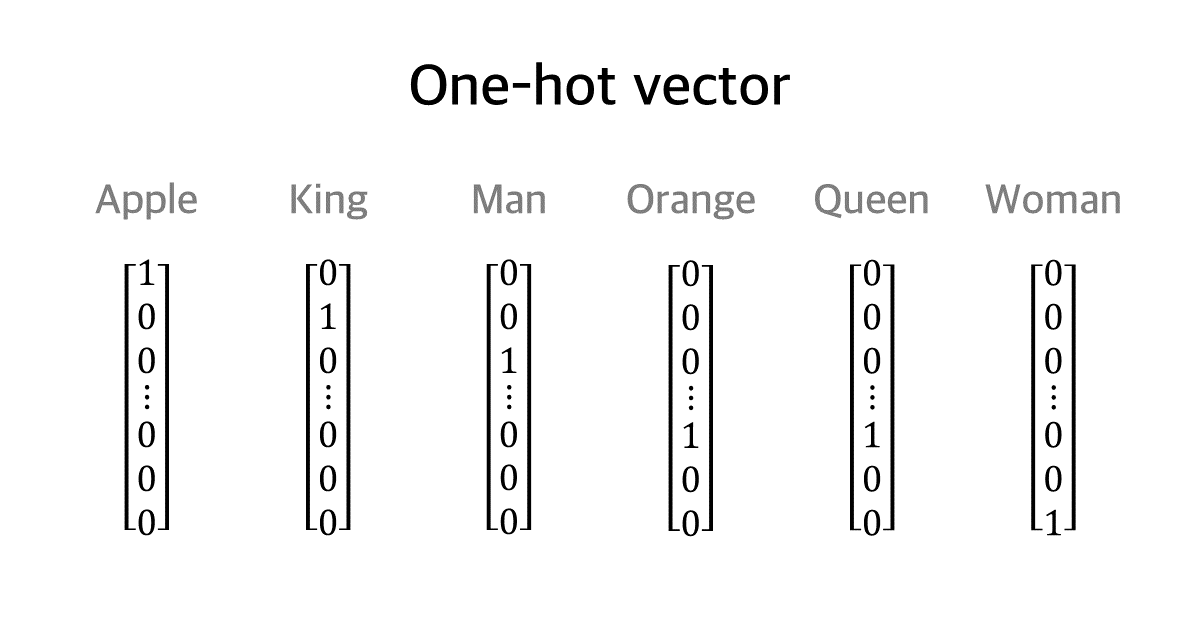
이 방식의 단점은 당연하게도 너무 단순하다는 점이다. 단지 단어를 숫자로 표현하기만 했을 뿐, 단어 사이의 관계나 단어의 의미 등 언어에서 필요한 표현법에 대해서는 전혀 알 수 없다. 따라서 이 방법을 보완하고자 나온 것이 Embedding vector 방법이다.
Embedding vector
Embedding vector 방법에서는 임베딩 행렬(embedding matrix)을 사용해서 각 단어가 특정 범주형 변수에서 어느 정도의 의미를 가지는지 표현한다. 예를 들어서 아래 예시에서 Man은 Gender라는 변주에 대해서 -1의 값을, Woman은 같은 범주에 대해서 1의 값을 가지고 있다. 참고로 음수가 "없다" 또는 "적다"라는 뜻인 것 아니다. 이 값들은 Vector이므로 방향성을 가지고 있다. 즉 Man과 Woman은 Gender에 있어서는 정반대 방향이라는 것을 보여주는 것이다. 또 다른 예시로 King과 Queen은 Royal이라는 변수에 대해서는 각각 0.93, 0.95인데 이는 이 두 단어가 거의 비슷한 수준으로 Royal이라는 특성을 가진다는 것을 나타낸다.
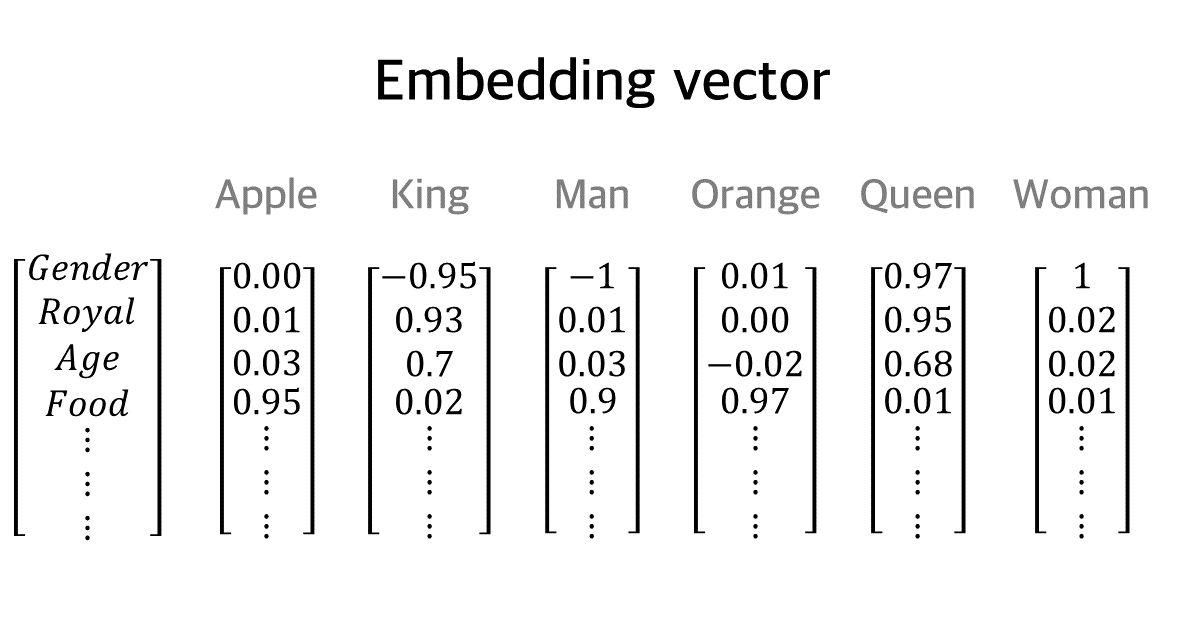
이 방식은 단어 사이의 관계 뿐만 아니라 단어가 내포하고 있는 다양한 문맥이나 함축된 의미를 표현하기에 매우 적합해보인다. 그러나 한 단어를 임베딩하기 위해서 들여야 하는 공수도 그만큼 많아진다. 어떻게 하면 이런 임베딩 벡터를 생성할 수 있을까? 데이터 라벨링과 같은 방법을 사용해도 되지만, 금전이나 시간이 매우 많이 소요되는 방법이다. 대규모의 임베딩 테이블을 얻기 위해서는 자동화된 방법이 필요하다. 이런 방법 중 대표적인 것이 Word2Vec 방식이다.
Word2Vec
구글에서 발명한 Word2Vec은 자동화된 training을 통해서 임베딩 테이블을 얻어내는 방법론이다. 이 방법론은 한 단어의 문맥(context)이란 문서에서 그 단어가 등장 할 때 앞뒤 단어들과 관련이 있다는 직관을 담고 있다.
아래 예시는 Word2Vec 중에서도 CBOW(continuous Bag of Words) 방식이다. 이 방식에서는 문장에서 임베딩을 얻고 싶은 단어가 중간단어(center word)가 되고, 그 앞뒤 단어들이 주변단어(context word)가 된다. CBOW 방식은 주변단어를 통해서 중간단어를 알아내는 것을 목표로 한다. 이때 context word의 갯수를 윈도우(window)라고 하는데, 윈도우를 통해서 문맥을 어디까지 고려할 것인지 결정할 수 있다. 만약 윈도우를 크게 만들면 더 넓은 문맥을 고려한다는 뜻이 되고, 작게 만들면 좁은 문맥을 고려한다는 뜻이 된다.

CBOW 방식의 동작법은 다음과 같다:
- 입력층(Input Layer)에서는 주변단어들의 One-hot vecter를 입력으로 받는다. 예를 들어 "the cat sat on the mat"이라는 문장에서 "the", "sat", "on", "the"를 주변 단어로 간주하고, 이들의 원-핫 벡터를 입력으로 사용한다.
- 투사층(Projection Layer)에서는 입력 벡터들의 평균을 계산하고, 이를 임베딩 행렬과 곱해서 임베딩 벡터(또는 임베딩 테이블)를 생성한다. 여기서 임베딩 행렬은 모델이 학습하는 파라미터로, 각 단어의 원-핫 벡터를 저차원의 실수 벡터로 매핑하는 역할을 한다.
- 출력층(Output Layer)에서는 투사층을 통해 생성된 임베딩 벡터를 입력으로 받아, 중심 단어의 원-핫 인코딩 벡터를 예측한다. 즉, 중심 단어를 주변 단어들을 통해 예측하게 된다.
이 이후부터는 대부분의 모델 학습 과정과 같다. 예측된 중심 단어와 실제 중심 단어 간의 오차를 계산하여 손실을 구하고, 이 손실을 기반으로 역전파를 통해서 파라미터(여기서는 임베딩 벡터)를 업데이트한다.
참고 문헌
05-3. word2vec 이란?
``` 05-3 작성자 : 구현회 ``` [TOC] Word2Vec은 구글의 토마스 미콜로프가 이끄는 연구팀에서 2013년에 발표한 기술로 자연어 처리(NLP) 워…
wikidocs.net
'🤖AIML' 카테고리의 다른 글
| numpy에서 자주 쓰이는 함수 및 기능들 외우기 (creation, manipulation, search, math, sorting) (0) | 2025.04.18 |
|---|---|
| 파이썬 멀티 프로세싱(multiprocessing)으로 CPU 여러 개 사용한 데이터 전처리 및 feature 추출 가속화 (0) | 2024.05.03 |
| Apple M3 Max 칩의 변화 및 M3 Ultra/M3 Extreme 칩에 대한 루머 (1) | 2024.03.29 |
| [Keras] keras.layers.GlobalAveragePooling1D 레이어 이해하기 (0) | 2024.03.11 |
| [Keras] keras.layers.Dropout 레이어 이해하기 (0) | 2024.02.21 |
임베딩과 벡터란
최근 LLM이 대세로 떠오르면서 "임베딩", "벡터" 등의 단어를 듣게 되는 일이 많아졌다. NLP에서 임베딩과 벡터란 무엇일까? NLP에서 사용하는 토큰이란 단어나 형태소 등의 자연어이다. 이 자연어를 기계가 이해할 수 있는 수학적 표현인 벡터로 바꾸는 것을 임베딩이라고 한다. 쉽게 이야기하자면 언어를 숫자로 바꾸는 게 임베딩이다.
ChatGPT 등 몇몇 서비스에서는 임베딩 기능도 API를 호출해서 쓸 수 있다. 만약 임베딩을 해야 한다면 좋은 언어 모델을 가진 서비스의 임베딩을 쓰는 게 필수적인데, 이 부분이야말로 LLM에서 가장 공수가 많이 들어간 부분이기 때문이다. 왜 좋은 임베딩을 쓰는 것이 필수적인지를 여러 임베딩 방법을 배우면서 알아보자.
One-hot vector
임베딩 중 가장 단순하고 쉬운 방법으로는 One-hot vector 방법이 있다. 예를 들어서 임베딩을 생성해야 하는 단어가 N개 있다고 하면, 1*N 행렬을 만든 후 해당 단어를 의미하는 위치에는 1을, 나머지 위치에는 0을 주어서 그 단어를 표현하는 방식이다. 예를 들어서 아래의 예시에서 Apple은 [1, 0, 0, ..., 0, 0, 0]이 되고, Woman은 [0, 0, 0, ..., 0, 0, 1]이 된다.
이 방식의 단점은 당연하게도 너무 단순하다는 점이다. 단지 단어를 숫자로 표현하기만 했을 뿐, 단어 사이의 관계나 단어의 의미 등 언어에서 필요한 표현법에 대해서는 전혀 알 수 없다. 따라서 이 방법을 보완하고자 나온 것이 Embedding vector 방법이다.
Embedding vector
Embedding vector 방법에서는 임베딩 행렬(embedding matrix)을 사용해서 각 단어가 특정 범주형 변수에서 어느 정도의 의미를 가지는지 표현한다. 예를 들어서 아래 예시에서 Man은 Gender라는 변주에 대해서 -1의 값을, Woman은 같은 범주에 대해서 1의 값을 가지고 있다. 참고로 음수가 "없다" 또는 "적다"라는 뜻인 것 아니다. 이 값들은 Vector이므로 방향성을 가지고 있다. 즉 Man과 Woman은 Gender에 있어서는 정반대 방향이라는 것을 보여주는 것이다. 또 다른 예시로 King과 Queen은 Royal이라는 변수에 대해서는 각각 0.93, 0.95인데 이는 이 두 단어가 거의 비슷한 수준으로 Royal이라는 특성을 가진다는 것을 나타낸다.
이 방식은 단어 사이의 관계 뿐만 아니라 단어가 내포하고 있는 다양한 문맥이나 함축된 의미를 표현하기에 매우 적합해보인다. 그러나 한 단어를 임베딩하기 위해서 들여야 하는 공수도 그만큼 많아진다. 어떻게 하면 이런 임베딩 벡터를 생성할 수 있을까? 데이터 라벨링과 같은 방법을 사용해도 되지만, 금전이나 시간이 매우 많이 소요되는 방법이다. 대규모의 임베딩 테이블을 얻기 위해서는 자동화된 방법이 필요하다. 이런 방법 중 대표적인 것이 Word2Vec 방식이다.
Word2Vec
구글에서 발명한 Word2Vec은 자동화된 training을 통해서 임베딩 테이블을 얻어내는 방법론이다. 이 방법론은 한 단어의 문맥(context)이란 문서에서 그 단어가 등장 할 때 앞뒤 단어들과 관련이 있다는 직관을 담고 있다.
아래 예시는 Word2Vec 중에서도 CBOW(continuous Bag of Words) 방식이다. 이 방식에서는 문장에서 임베딩을 얻고 싶은 단어가 중간단어(center word)가 되고, 그 앞뒤 단어들이 주변단어(context word)가 된다. CBOW 방식은 주변단어를 통해서 중간단어를 알아내는 것을 목표로 한다. 이때 context word의 갯수를 윈도우(window)라고 하는데, 윈도우를 통해서 문맥을 어디까지 고려할 것인지 결정할 수 있다. 만약 윈도우를 크게 만들면 더 넓은 문맥을 고려한다는 뜻이 되고, 작게 만들면 좁은 문맥을 고려한다는 뜻이 된다.
CBOW 방식의 동작법은 다음과 같다:
- 입력층(Input Layer)에서는 주변단어들의 One-hot vecter를 입력으로 받는다. 예를 들어 "the cat sat on the mat"이라는 문장에서 "the", "sat", "on", "the"를 주변 단어로 간주하고, 이들의 원-핫 벡터를 입력으로 사용한다.
- 투사층(Projection Layer)에서는 입력 벡터들의 평균을 계산하고, 이를 임베딩 행렬과 곱해서 임베딩 벡터(또는 임베딩 테이블)를 생성한다. 여기서 임베딩 행렬은 모델이 학습하는 파라미터로, 각 단어의 원-핫 벡터를 저차원의 실수 벡터로 매핑하는 역할을 한다.
- 출력층(Output Layer)에서는 투사층을 통해 생성된 임베딩 벡터를 입력으로 받아, 중심 단어의 원-핫 인코딩 벡터를 예측한다. 즉, 중심 단어를 주변 단어들을 통해 예측하게 된다.
이 이후부터는 대부분의 모델 학습 과정과 같다. 예측된 중심 단어와 실제 중심 단어 간의 오차를 계산하여 손실을 구하고, 이 손실을 기반으로 역전파를 통해서 파라미터(여기서는 임베딩 벡터)를 업데이트한다.
참고 문헌
05-3. word2vec 이란?
``` 05-3 작성자 : 구현회 ``` [TOC] Word2Vec은 구글의 토마스 미콜로프가 이끄는 연구팀에서 2013년에 발표한 기술로 자연어 처리(NLP) 워…
wikidocs.net
'🤖AIML' 카테고리의 다른 글
| numpy에서 자주 쓰이는 함수 및 기능들 외우기 (creation, manipulation, search, math, sorting) (0) | 2025.04.18 |
|---|---|
| 파이썬 멀티 프로세싱(multiprocessing)으로 CPU 여러 개 사용한 데이터 전처리 및 feature 추출 가속화 (0) | 2024.05.03 |
| Apple M3 Max 칩의 변화 및 M3 Ultra/M3 Extreme 칩에 대한 루머 (1) | 2024.03.29 |
| [Keras] keras.layers.GlobalAveragePooling1D 레이어 이해하기 (0) | 2024.03.11 |
| [Keras] keras.layers.Dropout 레이어 이해하기 (0) | 2024.02.21 |