There are two elements to Kubernetes objects
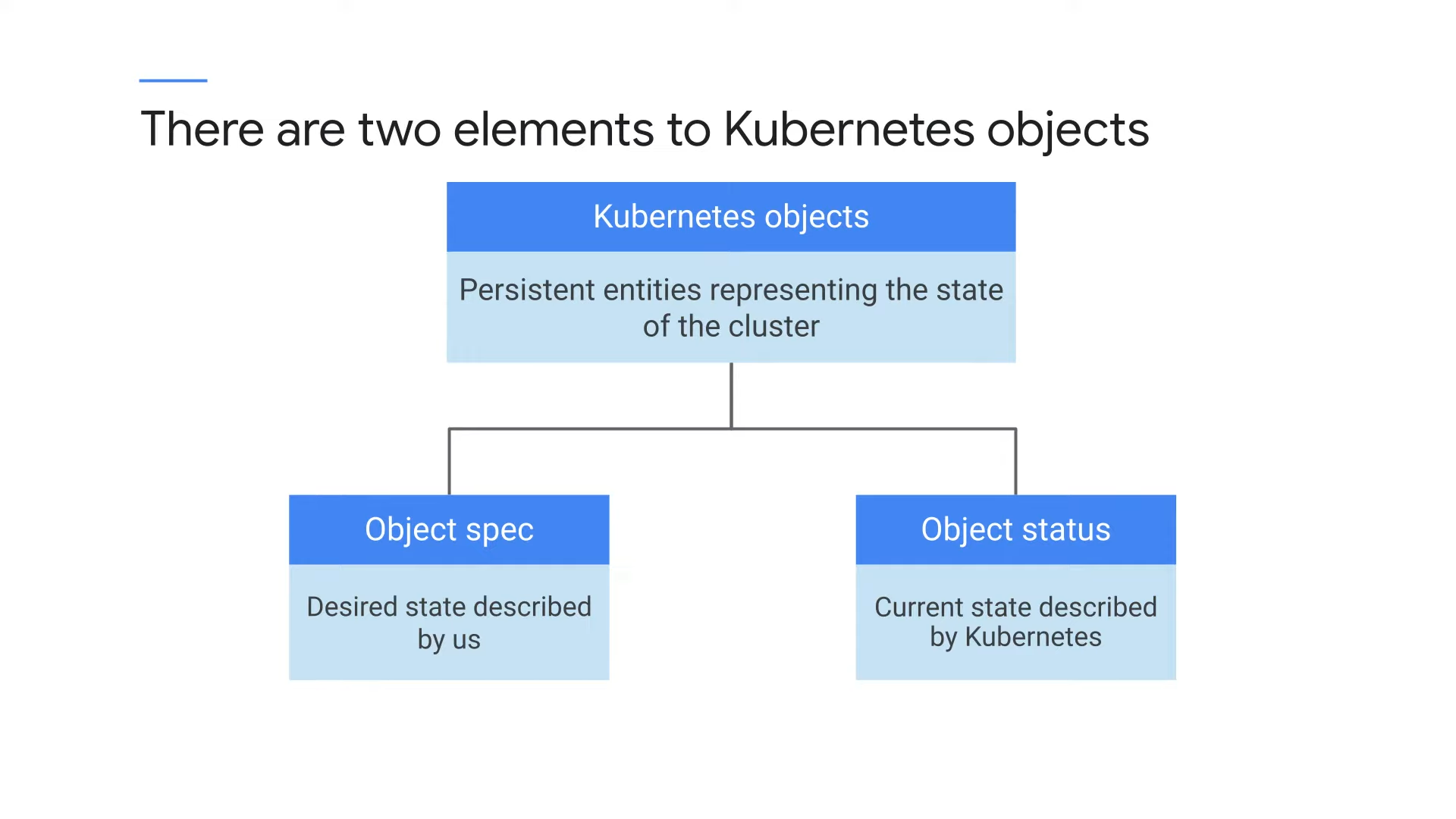
쿠버네티스에는 두 가지 중요한 컨셉이 있다. 객체의 스펙과 상태이다.
먼저 쿠버네티스의 객체란 무엇일까? 쿠버네티스에서 객체(Object)는 쿠버네티스 클러스터 내에서 관리되는 배포 가능한 엔터티를 나타낸다. 이러한 객체는 클러스터 내의 다양한 리소스를 정의하고 관리하는 데 사용된다.
쿠버네티스에서는 이렇게 사용할 객체의 ‘원하는 상태(desired status)’를 유지하는 것이 중요하다. 예를 들어, Pod이라는 객체가 있고, 이 객체가 3개 running 중인 상태를 유지해야 하는 상황이라고 하자. 이 상태를 유지하기 위해서는 사용자는 사용할 각 객체에 대한 스팩을 쿠버네티스에 제공해야 한다. 이 스팩을 통해 원하는 특성을 제공하여 객체의 원하는 상태를 정의할 수 있다. 객체의 상태는 쿠버네티스 제어 영역(Control plane)에서 제공한다.
쿠버네티스는 선언적 관리(Declarative Management)를 통해 선언된 객체의 상태를 유지하는 역할을 한다. 쿠버네티스의 선언적 관리는 원하는 상태를 명시적으로 선언하고, 쿠버네티스가 클러스터의 현재 상태와 원하는 상태 간의 차이를 감지하여 자동으로 조정하는 방식을 말한다. 이 개념은 쿠버네티스의 핵심 원칙 중 하나이며, 클러스터 리소스 및 애플리케이션의 배포, 업데이트 및 관리를 효율적이고 예측 가능한 방식으로 수행하는 데 중요한 역할을 한다.
Containers in a Pod share resources
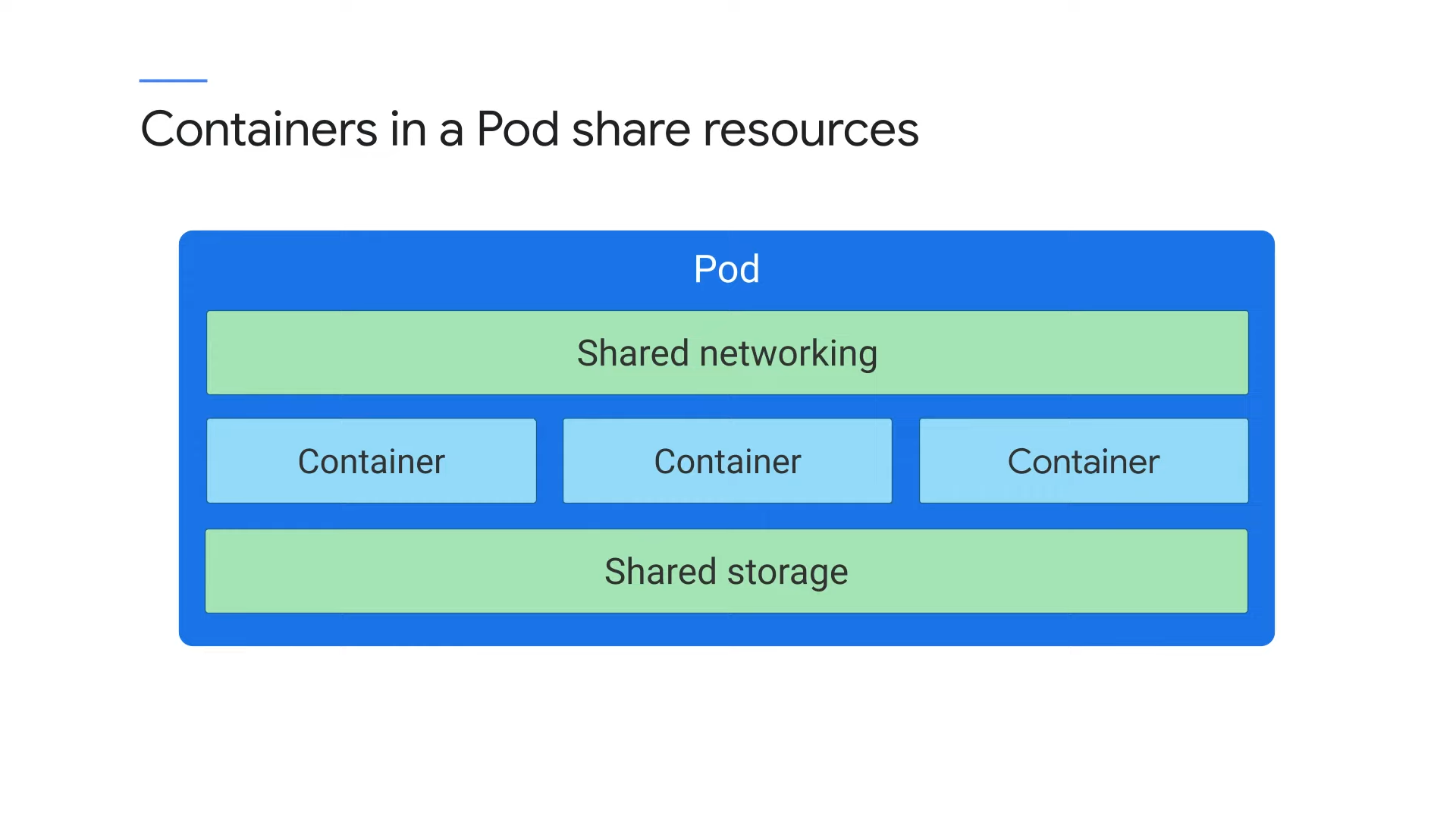
쿠버네티스에서 각 객체는 쿠버네티스가 호출하는 특정 유형 또는 종류이다. Pod는 쿠버네티스 모델의 기본 구성요소로 배포 가능한 가장 작은 쿠버네티스 객체이다. 쿠버네티스에서 실행하는 모든 컨테이너는 Pod에 존재한다. 포드는 컨테이너가 존재할 수 있는 환경을 제시하며, 하나 이상의 컨테이너를 수용할 수 있다. 하나의 포드에 하나 이상의 컨테이너가 있으면 이 둘은 긴밀하게 리소스를 공유한다. 이 리소스에는 네트워킹과 스토리지가 포함된다.
쿠버네티스는 하나의 포트에 고유한 IP를 할당한다. 하나의 포드 내의 모든 컨테이너는 IP 주소와 네트워크 포트는 물론 네트워크 네임스페이스도 공유한다.
같은 포드 내의 컨테이너들은 localhost 127.0.01을 통해 통신할 수 있다. 포드는 컨테이너 간에 공유할 스토리지 볼륨 집합을 지정할 수도 있다.
Desired state compared to current state

만약 우리가 “3개의 nginx 포드를 항상 실행 중인 상태로 관리하고 유지보수하라”고 쿠버네티스에 알렸다고 가정해보자. 그럼 쿠버네티스는 현재의 상태와 원하는 상태를 비교한다. 그리고 이 둘이 일치하지 않으면 쿠버네티스 제어 영역이 이 상황을 해결한다. 이러한 과정을 끊임없이 반복하면서 필요한 경우 상태를 수정한다.
Cooperating processes make a Kubernetes cluster work

그렇다면 쿠버네티스 클러스터는 어떻게 구성되어 있을까? 먼저, 쿠버네티스 클러스터는 컴퓨터가 필요하다. 일반적으로 이러한 컴퓨터는 가상 머신이지만, 물리적인 컴퓨터일 수도 있다. 한 컴퓨터는 제어 영역(control plane)이라고 불리고, 다른 컴퓨터들은 노드라고 불린다. 노드의 역할은 포드를 실행하는 것이다. 제어 영역의 역할은 전체 클러스터를 관리하는 것이다. 제어 영역에서 각 부분의 자세한 역할을 살펴보자.
kube-apiserver- 사용자와 직접 통신하는 영역으로, 클러스터의 상태를 보거나 변경하는 명령어를 수행하는 역할을 한다. 포드 시작과 같은 일들을 할 수 있다. kubectl 명령어를 사용하면 kube-apiserver에 연결하고 kubernetest api를 사용하여 통신할 수 있다.
- kubectl을 통해 command line 명령어를 api 호출로 변경할 수 있다.
- kube-apiserver는 들어오는 요청을 인증하고 이들이 승인되고 유효한지 확인하며 허용 제어를 관리한다.
- 그러나 kubectl만이 이 서버와 통신하는 것은 아니다. 사실, 클러스터 상태에 대한 모든 쿼리나 변경은 반드시 kube-apiserver에 전달되어야 한다.
etcd- 클러스터의 상태를 안정적으로 저장하는 데이터베이스로, 모든 클러스터 구성 데이터와 클러스터의 동적인 정보, 즉 어떤 포드가 실행 중이고 실행되어야 하는 지 등의 정보를 저장한다.
- etcd와는 절대 직접 통신하지 않는다. 대신 kube-apiserver가 시스템의 나머지 부분을 대신하여 데이터베이스와 상호작용한다.
kube-sheduler- 노드에 포드를 예약하는 역할을 한다. 이를 위해 각 포드의 요구사항을 평가하고 가장 적합한 노드를 선정한다.
- 그러나 노드에 파드를 띄우는 역할을 직접 진행하지는 않는다. 대신 노드에 아직 할당되지 않은 포드 객체를 발견할 때마다 노드를 선택하고 이 노드의 이름을 포드 객체에 쓰는 작업을 수행한다. 시스템에 포드를 실행하는 역할을 하는 것은 kubelet이다.
- kube-sheduler는 포드를 실행할 위치를 결정하기 위해 모든 노드의 상태를 알고 있으며, 하드웨어, 소프트웨어, 정책을 바탕으로 포드가 실행될 수 있는 위치에 대해서도 사용자가 정의한 제약조건을 따른다.
- 예를 들어, 특정 포드가 특정 양의 메모리가 있는 노드에서만 실행되도록 조건을 달거나, 같은 그룹의 포드가 같은 노드에서 실행되도록 또는 실행되지 않도록 안티어피니티 속성 만들 수 있다.
kube-controller-manager- kube-apiserver를 통해 지속적으로 클러스터의 상태를 모니터링한다. 클러스터의 현재 상태와 원하는 상태가 일치하지 않을 때마다 원하는 상태로 만들고자 변경을 시도한다. 이를 컨트롤러 관리자라고 한다. 많은 쿠버네티스 객체가 컨트롤러라고 하는 코드 루프에 의해 유지관리되기 때문이다. 이 코드 루프는 해결 작업을 처리한다.
- 특정한 종류의 컨트롤러를 사용하여 쿠버네티스 워크로드를 관리하게 된다. 예를 들어서 포드를 배포하고 하는 컨트롤러 객체로 모음으로써 관리할 수 있다. 다른 종류의 컨트롤러는 시스템 수준의 책임이 있다. 예를 들어, 노드 컨트롤러는 노드가 오프라인일 때 모니터링하고 응답하는 역할을 한다.
kube-cloud-manager- 기본 클라우드 제공업체와 상호작용하는 컨트롤러를 관리하는 역할을 한다. 예를 들어, google compute engine에서 쿠버네티스 클러스터를 수동으로 시작한 경우 kube-cloud-manager는 로드 밸런서나 스토리지 볼륨과 같은 google cloud 기능을 필요할 때 가져오는 역할을 한다.
node- 각 노드는 작업 제어 영역 구성요소 집합도 실행한다. 예를 들어 각 노드는 kubelet을 실행한다. 이는 각 노드에서 쿠버네티스의 에이전트라고 보면 된다. kube-apiserver가 노드에서 포드를 실행하려고 하면 해당 노드가 kubelet에 연결된다. kubelet은 컨테이너 런타임을 사용해 포드를 시작하고 준비 및 활성 프로브를 포함한 수명 주기를 모니터링한 다음 kube-apiserver에 다시 전달한다.
- 컨테이너 이미지에서 컨테이너를 실행하는 방법을 알고 있는 소프트웨어인 컨테이너 런타임은 GKE에서는 Docker의 런타임 구성요소인 containerd를 사용하는 것이다.
kube-proxy- 클러스터의 포드 간 네트워크 연결을 유지관리하는 역할을 한다. 오픈소스 쿠버네티스에서 kube-proxy는 Linux 커널에 내장된 iptables의 방화벽 기능을 사용해 이를 수행한다.
이 모든 요소를 설치하고 관리하는 건 어려운 일이다. 따라서 kubeadm이라는 오픈 소스 명령어를 통해 초기 설정을 자동화하기도 한다. 하지만 관리형 쿠버네티스 서비스를 사용하면 노드가 작동하지 않거나 하는 문제를 수동으로 해결할 필요가 없다.
GKE manages all the control plane components
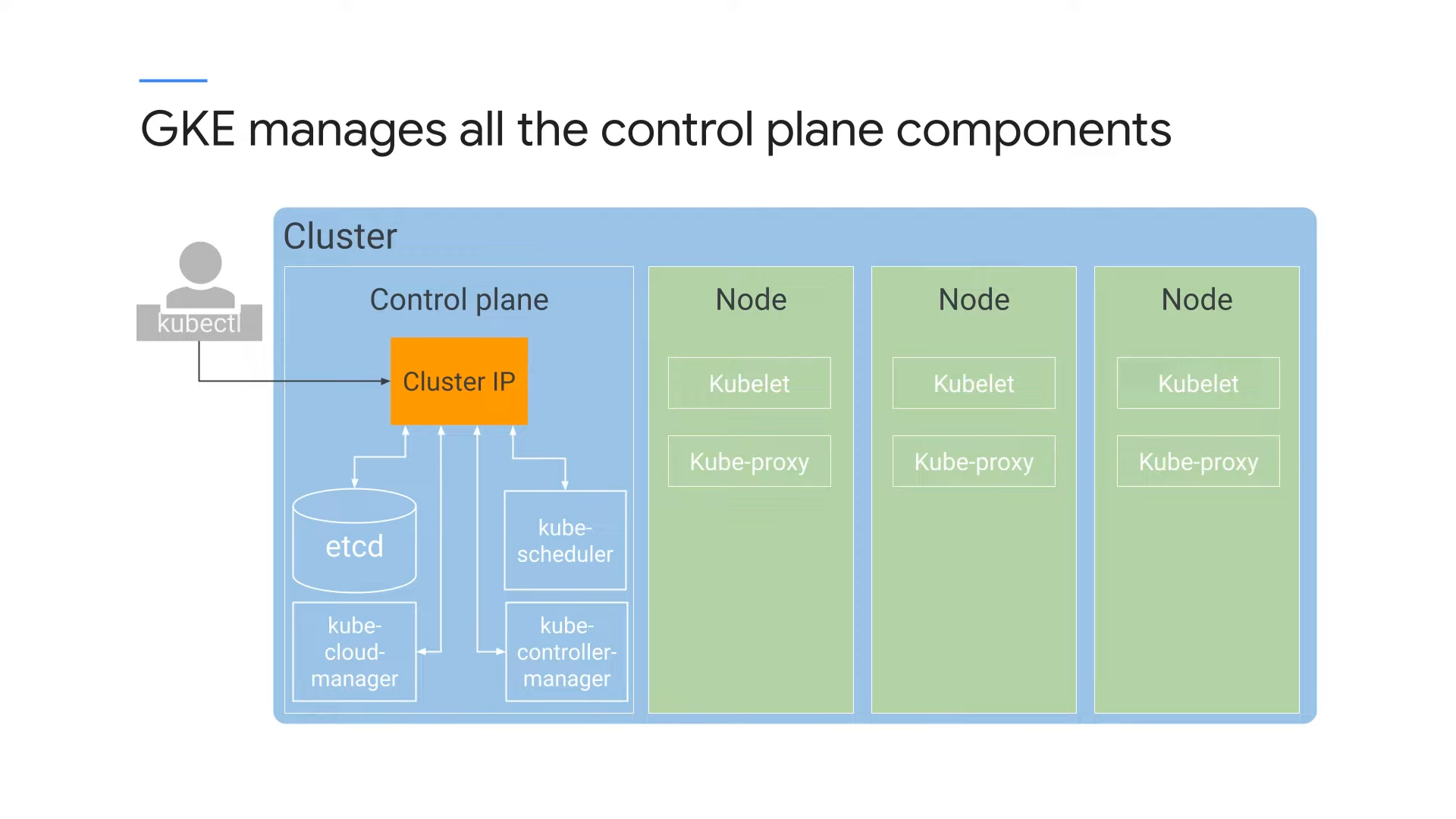
GKE는 사용자를 위해 모든 제어 영역 구성요소를 관리한다. 모든 GKE는 kubernetes API 요청을 보내는 IP 주소를 노출하지만 그 뒤에 있는 모든 제어 영역 인프라를 프로비저닝하고 관리한다. 또한 별도의 제어 영역이 필요하지 않다.
모든 쿠버네티스 환경에서, 쿠버네티스는 노드를 생성하지 않는다. 클러스터 관리자가 외부에 노드를 생성하고 이를 쿠버네티스에 연결하는 것이다. GKE는 이러한 프로세스를 대신해준다. 즉, compute engine을 통해 가상머신 인스턴스를 생성한 후 이를 쿠버네티스에 연결한다.
노드의 수명당 비용만 지불하면 되며, 제어 영역은 카운트하지 않는다.
Use node pools to manage different kinds of nodes
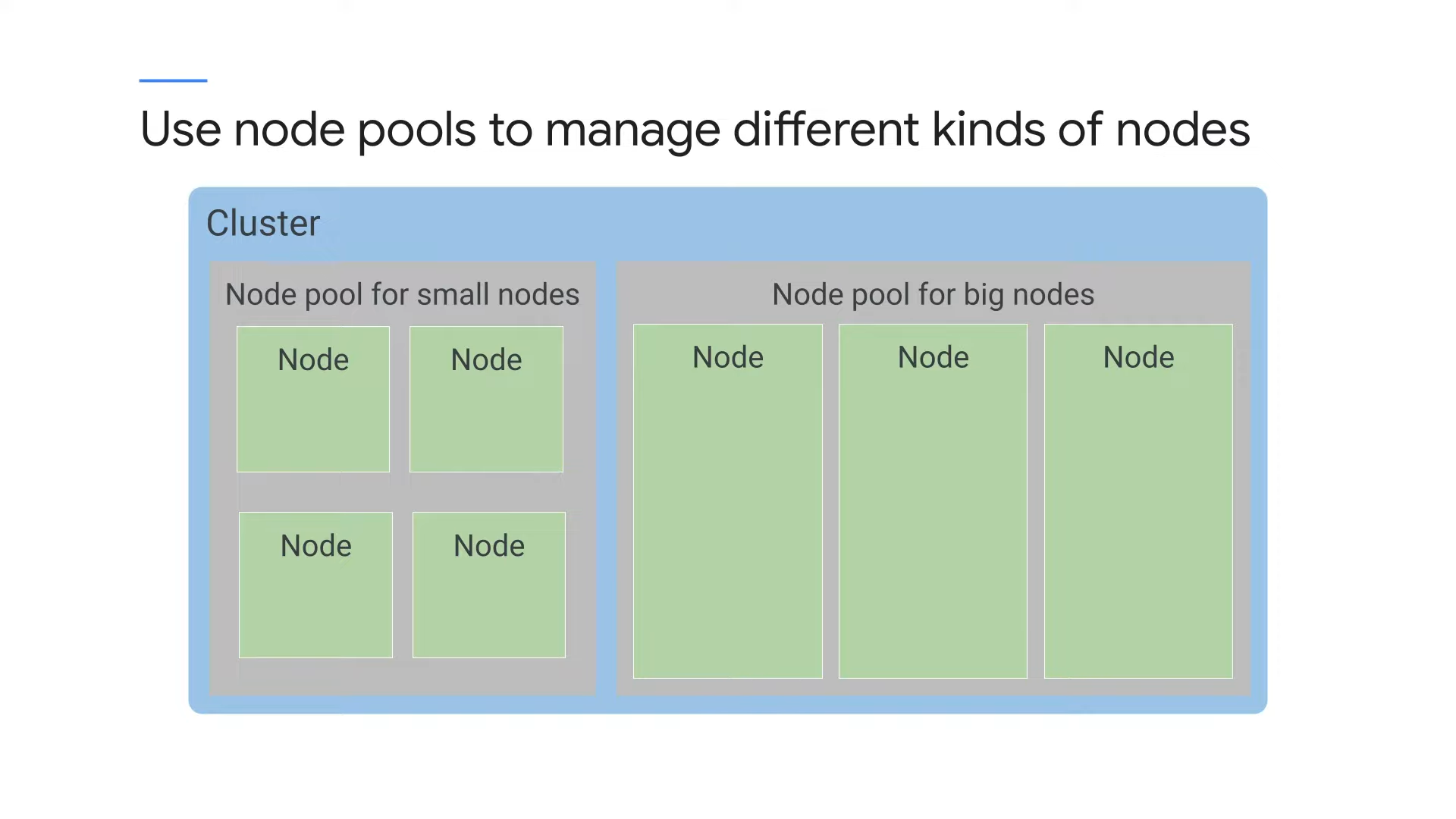
또한 GKE에서는 노드 풀을 선택하고 구성할 수 있다. 노드 풀이란 같은 CPU 세대나 메모리 양 같은 구성을 공유하는 클러스터 내 노드의 하위 집합이다. 이는 쿠버네티스가 아니라 GKE만의 기능이다.
노드 풀을 사용하면 자동 노드 확장, 클러스터 자동 확장 등을 사용 설정할 수 있다.
Zonal versus regional clusters

기본적으로 클러스터는 하나의 노드 풀에 3개의 같은 노드가 있는 단일 컴퓨팅 영역에서 실행된다. 더 많은 노드를 추가하면 가용성을 확보할 수 있지만, 전체 컴퓨팅 영역이 다운되면 어떻게 될까? 그렇게 되면 전체 서비스를 사용할 수 없게 될 것이다. GKE 리전 클러스터를 사용하면 이 문제를 해결할 수 있다. 리전 클러스터에는 클러스터를 위한 단일 API 엔드포인트가 있다. 제어 영역과 노드는 리전 내 여러 컴퓨팅 영역에 분산되어 있다. 리전 클러스터는 애플리케이션의 가용성이 단일 리전의 여러 영역에서 유지관리되도록 한다.
또한 제어 영역에 대한 가용성도 확보한다. 영역 전부에 대해서는 아니지만 하나 이상의 영역이 손실되더라도 애플리케이션과 관리 기능이 유지될 수 있다.
기본적으로 리전 클러스터는 3개의 영역에 분산되어 있고 각 영역은 1개의 제어 영역 및 3개의 노드를 포함하고 있다. 이 수는 늘어나거나 줄어들 수 있다. 예를 들어 영역 1에 노드 5개가 있으면 다른 영역에도 같은 수의 노드가 존재하게 되기 때문에, 노드는 총 15개가 된다.
영역 클러스터와 리전 클러스터는 한 번 구축되면 서로 바꿔서 변경할 수 없다.